Kuberenetes 모니터링 아키텍쳐
Kubernetes cluster는 여러 대의 노드로 구성되며 이 노드 안에는 또 다시 Container, Pod, Service 등과 같은 애플리케이션 운영 요소들이 자리잡고 있다. 여러 개의 애플리케이션을 운영할 때 어느 애플리케이션이 리소스를 많이 사용하는지, 어느 서비스에 네트워크 I/O가 부하가 걸리는지, 병목현상이 어디서 일어나는지에 대해 파악이 가능하고 이에 맞춰 미리 스케일아웃이 필요한지 판단하는데에 큰 도움을 줄 수 있다고 생각한다.
Kubernetes 모니터링 아키텍쳐
용어 설명
모니터링 아키텍쳐를 설명하기 전에 Kubernetes 에서는 메트릭을 아래의 두 가지로 나누고 있다.
- System metrics : 모든 개체에서 확인할 수 있는 일반적인 메트릭 (e.g. 컨테이너, 노드 등에서 확인할 수 있는 CPU/memory 사용량) Core metrics와 non-core metrics로 구분
- core metrics : kubernetes가 이해하고 내부 컴포넌트의 동작과 코어 유틸리티 등을 운영하는데에 사용됨. 리소스 예측, 초기 자원이나 수직적 오토 스케일링, 클러스터 오토 스케일링, HPA(Horizontal Pod Autoscailer) 등을 포함하는 scheduling이나 kubernetes dashboard,
kubectl top과 같은 명령어를 통해 직접적으로 사용되는 메트릭. - non-core metrics : kubernetes에서 이해할 수 없으며 코어 메트릭에 포함되는 정보와 더불어 다른 메트릭도 포함된 것.
- core metrics : kubernetes가 이해하고 내부 컴포넌트의 동작과 코어 유틸리티 등을 운영하는데에 사용됨. 리소스 예측, 초기 자원이나 수직적 오토 스케일링, 클러스터 오토 스케일링, HPA(Horizontal Pod Autoscailer) 등을 포함하는 scheduling이나 kubernetes dashboard,
- Service metrics : 애플리케이션 코드에 의해 정의되고 관측되는 메트릭. (e.g. API 서버에서 발생한 500에러 횟수) kubernetes infra 요소에 의해 생성되는 메트릭과 유저 애플리케이션에 의해 생성되는 메트릭으로 구분한다. HPA 를 위한 입력값으로도 사용되는 서비스 메트릭은 custom metric이라고 부르기도 함.
Kubernetes는 애플리케이션의 상태를 보기위한 메트릭만 모니터링의 대상으로 정의하기 때문에 애플리케이션에서 발생되는 로그(사용자 행위 등)는 모니터링 대상에서 제외하고 생각한다. (쿠버네티스에서 자체적으로 지원하지 않는다는 뜻)
아키텍쳐 요구사항
쿠버네티스에서 정의하는 모니터링 아키텍쳐에 대한 요구사항은 아래와 같다.
- Kubernetes의 코어 솔루션을 포함하고
- node, pod, container의 코어 시스템 메트릭이 Kubernetes 코어 API에서 사용이 가능하도록(이해가 가능하도록) 해야함.
- Kubelet이 코어 kubernetes 컴포넌트가 정상적으로 동작하도록 하는 제한된 메트릭만 내보낼 수 있게 해야함. (…?)
- 5000개의 노드까지 스케일업 가능해야 함.
- 모든 Deployment 구성에서 실행될 수 있도록 충분히 작아야 함.
- 초기 자원과 vertical pod autoscaling 및 클러스터 분석 쿼리를 지원하는 등 코어 Kubernetes에만 의존하는 기록 데이터를 제공하는 뛰어난(out-of-the-box) 솔루션이 포함되어야 함.
- 코어 Kubernetes가 아니면서 HPA와 같은 서비스 메트릭을 요구하는 컴포넌트와 통합될 수 있는 서드파티 모니터링 솔루션을 허용해야 함. (외부 모니터링 솔루션과 충돌하지 않아야 한다는 뜻인듯..)
아키텍쳐
본격적인 Kubernetes 모니터링의 아키텍쳐. Core metrics pipeline과 Monitoring pipeline 두 가지로 구분지어 아키텍쳐를 설계하였다.
Core metrics pipeline
Kublet, resource estimetor, metric-server(경량화된 Heapster), master metrics API를 서빙하는 API 서버 들의 요소로 구성되어 있다. 이 메트릭들은 스케줄링 로직과 같은 코어 시스템 컴포넌트나 kubectl top 과 같은 간단한 UI 컴포넌트에서 사용된다. 서드파티 모니터링 시스템과 의 통합은 고려하지 않음.
리소스 메트릭을 이용해 HPA가 동작하기 위해서는 metric-server가 필요하다 한다. kubeadm으로 클러스터를 구성하였다면 https://github.com/kubernetes-sigs/metrics-server/releases 에서 yaml을 받아 배포할 것.
Monitoring pipeline
core metrics만을 위한 Metrics pipeline을 따로 설계한 이유는 코어 컴포넌트에 사용하지 않기 때문에 유연한 모니터링 파이프라인을 구성하기 위해서라고 한다. 쿠버네티스는 자체적인 Monitoring pipeline을 제공하지는 않지만 간단하게 설치가 가능하다.
모니터링 파이프라인에는 아래의 메트릭들이 포함될 수 있다.
- Core system metrics
- non-core system metrics
- 사용자 애플리케이션 컨테이너에서 나온 service metrics
- kubenetes infra 컨테이너에서 나온 service
Infrastore
쉽게 정리 : 생성된 메트릭들을 다양한 유즈케이스를 재확인하기 위해 필요한 쿼리들을 재사용 가능한 형태로 저장해두고 API로 제공하는 컴포넌트코어 시스템 메트릭과 이벤트에 대한 질의(historical queries)를 제공하는 컴포넌트. 하나 이상의 API를 노출하여 다음과 같은 경우의 유즈케이스를 핸들링한다.
- 초기 자원할당
- 수직적 오토스케일링
- oldtimer API
- debugging, capacity planning 등을 위한 decision-support queries
- Kubernetes Dashboard 내 사용량 그래프
모니터링 파이프라인은 위와 같은 다양한 메트릭을 수집하여 커스텀 메트릭을 보고 오토스케일링을 하는 HPA나 Infrastore에 이러한 메트릭들을 제공하기 위해 사용된다. 주로 사용되는 모니터링 파이프라인 조합은 아래와 같다.
- cAdvisor + collectd + Heapster
- cAdvisor + Prometheus
- snapd + Heapster
- snapd + SNAP cluster-level agent
- Sysdig
cAdvisor
컨테이너에 대한 정보를 수집하고 가공하여 내보내는 데몬 서비스. 기간별 리소스 사용량, 리소스 분리 매개 변수, 네트워크 통계 등에 대한 정보를 유지한다.
(원문에는 cAdvisor + Prometheus 조합을 예시로 모니터링 파이프라인 수집을 설명하는 부분이 있음. / 여기서는 다음 포스팅에 프로메테우스의 기본 동작을 설명하기 위해 생략)
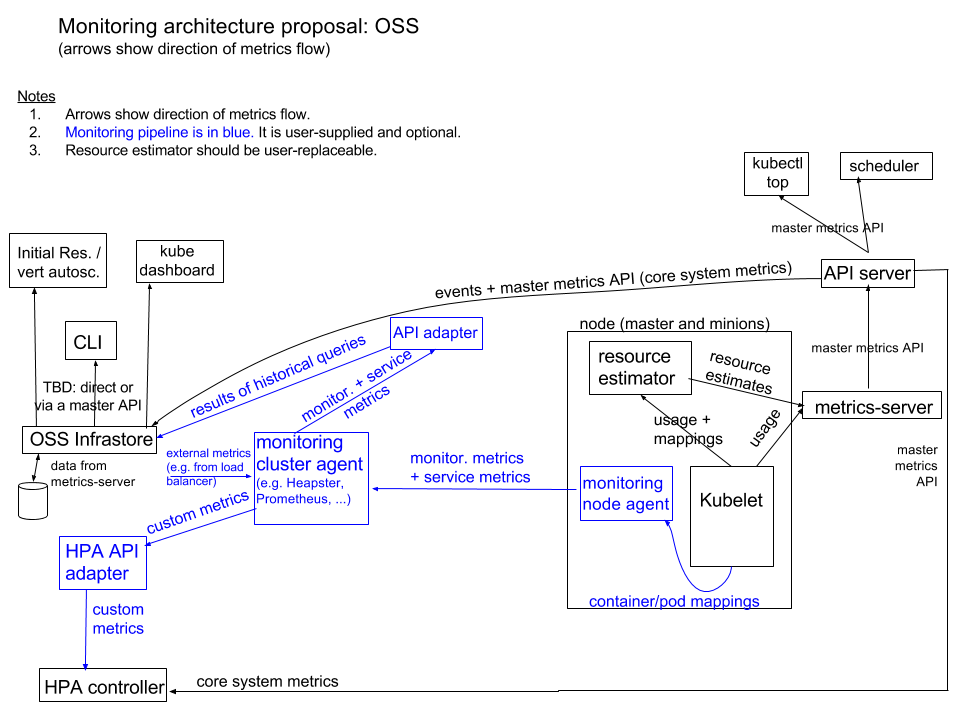
검은 색은 core metric pipeline 구성요소, 파란 색은 monitoring pipeline 구성요소
정리
다소 어려운 내용이였지만 kubernetes 모니터링 구조의 설계 원칙과 요구사항, 유연한 파이프라이닝을 위한 core metric과 나머지 metric으로 분리한 구조, 수집된 metric을 kubernetes에서 어떻게 사용하는지 등을 이해하는데 도움이 되었다. 물론 실제로 모니터링 시스템을 구축하는데 위와 같은 내용을 다 알아야 할 필요는 없겠지만 향후 클러스터를 확장하게 되면 동작의 이해가 필요할 것 같아서 정리해보았다.