Kuberenetes 모니터링 시스템 구축(prometheus, grafana)
지난 번 모니터링 아키텍쳐 포스팅에 이어 Prometheus 를 기반으로 하는 모니터링 시스템에 대한 간략한 설명과 실제 구축 예시를 정리하고자 한다.
모니터링 도구 선정
모니터링 방식에는 크게 push-based와 pull-based가 존재한다고 한다. Push-based 방식은 운영중인 각 서버마다 모니터링 에이전트를 설치해 정보를 수집하고, 이를 모니터링 서버로 보내는 방식이다. 대표주자로는 Graphite, Beats가 있다. Pull-based 방식은 반대로, 일정 간격을 두고 모니터링 서버에서 각 수집대상인 서버(client)를 찾아 메트릭을 직접 가져오는(scrape) 방식이다. 대표주자로는 Prometheus가 있다.
보통 Kubernetes에서는 Pod이나 Container가 지워지고 다시 만들어지는 경우가 잦기 때문에 모니터링 대상이 동적이다. 이러한 상황에서 업데이트나 새로 배포할 때마다 Push-based 모니터링 시스템의 에이전트를 매 번 설치하기 보다는 수집대상을 직접 찾고 가져오는 Pull-based가 잘 어울린다고 볼 수 있다.
push-based, pull-based 각각의 장단점이 있으나 이번 글의 취지와는 벗어나므로 나중에 다루기로..
Prometheus
Pull based 모니터링 툴이다. 메트릭을 수집하여 시계열 데이터로 저장하며 측정 지표는 기록된 타임스탬프와 함께 레이블 이라고 하는 선택적인 key-value 쌍과 함께 저장된다.
alert manager를 통해 사용량 경고 등을 보낼수도 있고, grafana와 통합하여 강력한 메트릭 시각화도 가능하다.
주요 기능
- 메트릭 이름과 key-value 쌍으로 식별되는 다차원 시계열 데이터 모델
- 다차원의 데이터를 조회할 수 있는 PromQL
- 분산 스토리지에 대한 의존성이 없음.
- HTTP 프로토콜을 통한 Pull 기반의 시계열 수집
- 중개 gateway를 통한 pushing 기법
- 서비스 디스커버리나 정적 설정을 통한 대상 식별
- 다양한 모드의 graphing, dashboarding 지원
프로메테우스가 제공하지 않는 것
다음과 같은 것들이 필요하면 다른 솔루션을 추가로 사용해야 한다.
- 원시 로그 / 이벤트 수집 : Loki, Elastic stack
- 요청 추적(Request Tracing) : OpenMetrics, OpenTelemetry
- 이상 감지(Anomalt Detection)
- 장기 보관 및 고가용성 : Prometheus Operator, Thanos 등
- 스케일링 : Prometheus Operator, Thanos 등
- 사용자 인증 관리
구조
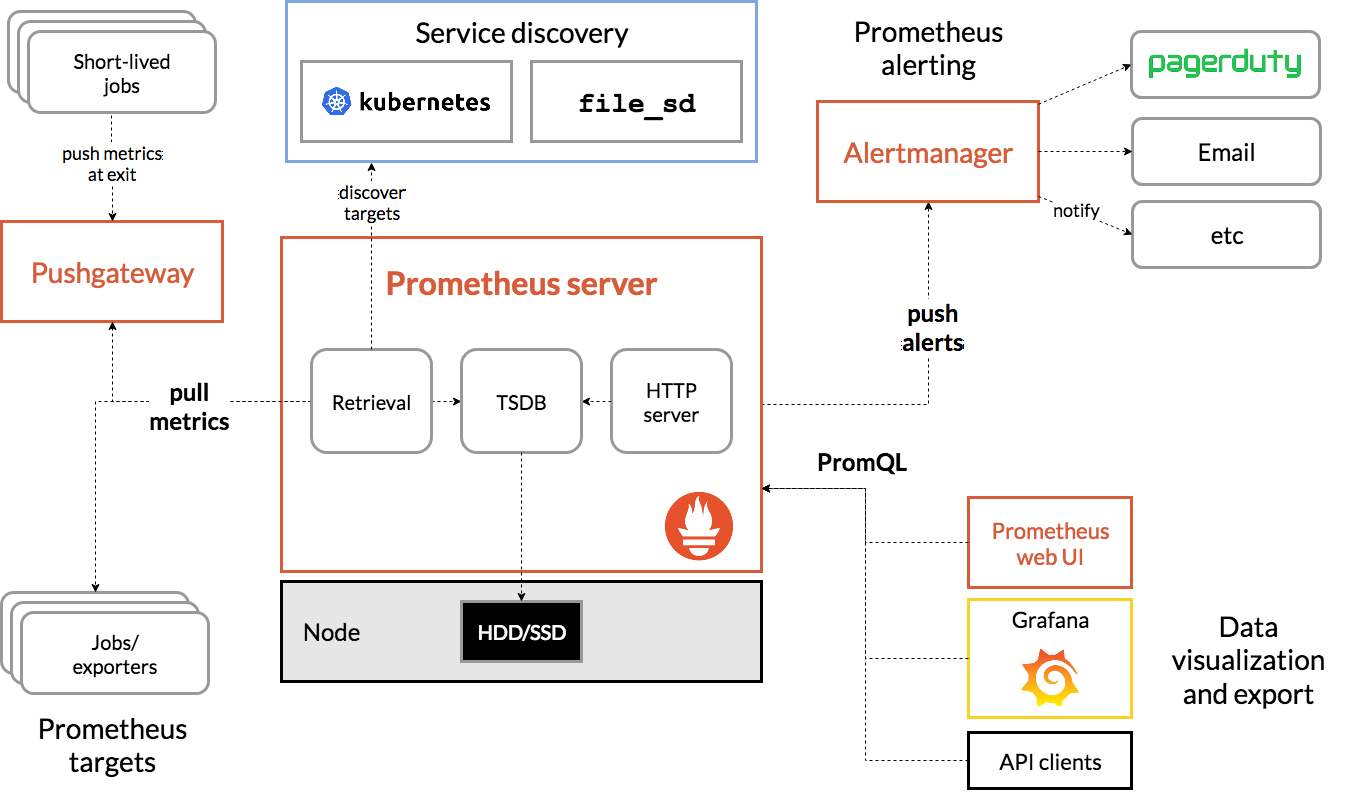
Jobs/Exporters
Job은 Prometheus 서버에 관점에서 바라보았을 때 메트릭 수집이 가능한 여러 인스턴스를 동일한 목적을 기준으로 묶어놓은 집합체이다. prometheus.yml(프로메테우스 설정파일)의 scrape_configs 속성에 값을 넣어 지정해줄 수 있다.
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['prometheus-server.default.svc.cluster.local:9090']
labels:
group: "prometheus"
- job_name: 'node'
scrape_intervbal: 5s # default 15s
# service-discovery를 이용해 동적으로 변경되는 타겟에도 대응이 가능하다.
static_configs:
- targets: ['prometheus-node-exporter-1.default.svc.cluster.local:8080', 'prometheus-node-exporter-2.default.svc.cluster.local:8080']
labels:
group: "production"
- targets: ['prometheus-node-exporter-3.default.svc.cluster.local:8080']
labels:
group: "canary"
인스턴스는 메트릭 수집이 가능하다는 것을 전제로 하기 때문에 주로 그 대상은 Exporter가 된다.
별도의 지정이 없으면 타겟의 /metrics 경로로 메트릭을 요청한다.
참고로 위의 scrape_config 는 참고용 예시일 뿐이고 kubernetes 에서 운영될때는 하단에 설명할 service discovery를 이용해 다르게 작성된다.
Exporter는 metrics pull 요청이 들어오면 요청 당시의 데이터를 리턴한다. (중간중간 값을 저장하지 않고 요청 시점의 데이터만 리턴) Kubernetes에서 주로 사용되는 Exporter는 Node-exporter와 kube-state-metrics가 있다.
Node-exporter는 클러스터를 구성하는 각 노드에 배포되어 CPU, Memory, Network I/O, Disk I/O 등의 메트릭을 수집한다. 모든 노드에 배포된다는 점이 Push-base 모니터링 시스템의 에이전트와 비슷해보일 수 있으나 기본적으로 수집하여 가지고 있다가 Prometheus 서버에서 요청이 들어올 때 내보낸다는 차이가 있으며, 모든 Exporter가 모니터링 대상에 배포되는 것은 아니다.
kube-state-metrics은 Kubernetes API를 이용하여 대부분의 Kubernetes 오브젝트에 대한 메트릭을 수집한다. Kubernetes API를 이용하기 때문에 하나의 Exporter만 있으면 된다.
요약 Exporter는 모니터링 대상의 Metric을 수집 -> Prometheus 데이터 모델로 변환 -> Metric 요청 시 전송
다양한 Exporter에 대해서 알아보면 공식 홈페이지의 Exporters 문서를 참고.
PushGateway
Exporter와 같이 메트릭을 수집하는 용도의 Component 이지만 설계 목적과 동작 방식이 상이하다. 앞서 설명했듯, Prometheus는 기본적으로 pull 기반의 모니터링 툴이지만 모니터링 대상이 임시로 만들어지는 컴포넌트일 경우 Exporter로 메트릭을 수집하기는 어렵다. 예를 들어, 서비스 레벨의 배치 잡들은 해당 작업을 수행하기 위해 Pod, 컨테이너가 생성되었다가 수행중인 작업이 모두 종료되면 컨테이너와 Pod 모두 사라진다. 이때, 해당 잡을 실행하면서 발생한 메트릭은 Pod이 사라지면 수집할 수 없게된다. 이런 제한적인 상황에서만 사용하도록 만들어진 것이 PushGateway 이다.
실행되는 배치 잡에서 중간에 위치한 PushGateway로 메트릭을 push 해두고 Prometheus 서버에서 메트릭 요청을 PushGateway로 보내어 배치 잡의 메트릭을 수집하는 형태로 메트릭 수집이 이루어진다. 배포된 잡이 PushGateway로 메트릭을 push하기 위해서는 각 언어별 prometheus 라이브러리를 사용해야 하는데, 내가 가장 많이 사용하는 Java의 예시 코드는 아래와 같다.
void executeBatchJob() throws Exception {
CollectorRegistry registry = new CollectorRegistry();
Gauge duration = Gauge.build()
.name("my_batch_job_duration_seconds").help("Duration of my batch job in seconds.").register(registry);
Gauge.Timer durationTimer = duration.startTimer();
try {
// Your code here.
// This is only added to the registry after success,
// so that a previous success in the Pushgateway isn't overwritten on failure.
Gauge lastSuccess = Gauge.build()
.name("my_batch_job_last_success").help("Last time my batch job succeeded, in unixtime.").register(registry);
lastSuccess.setToCurrentTime();
} finally {
durationTimer.setDuration();
PushGateway pg = new PushGateway("127.0.0.1:9091");
pg.pushAdd(registry, "my_batch_job");
}
}
// 출처 : https://prometheus.github.io/client_java/io/prometheus/client/exporter/PushGateway.html
각 언어별로 방법이 다른 듯 하니 Pushing Metrics 문서를 참고.
공식 문서에서는 PushGateway는 앞서 설명한 배치 잡과 같은 제한된 상황에서만 사용하도록 강력하게 권고하고 있다. 그 이유는 아래와 같다.
- 단일 PushGateway로 다수의 인스턴스를 모니터링하면 PushGateway는 장애지점이 되기 쉬우며 잠재적 병목현상 유발 컴포넌트가 된다.
- Exporter를 통해 scrape 할 때마다
up메트릭을 이용한 Prometheus 서버의 자동 인스턴스 health 모니터링 지표를 볼 수 없다. - Pushgateway 특성 상 한 번 들어온 시리즈는 수동으로 API를 통해 삭제하지 않는 한 Prometheus 서버에 지속적으로 노출된다.
Proxy Forwarding 등을 통해 접근할 수 없는 곳에 모니터링 대상이 있는 경우에도 사용하는 대안이라는 글을 많이 본 것 같다. 아직 공감은 되지 않음.
Prometheus server
Retreival
Service Discovery로부터 모니터링 대상 목록을 읽고, Job 들을 순회하면서 Pull 방식으로 metric 요청을 보내고 받아오는 역할을 함.
Service Discovery
위의 Jobs/Exporters에서 prometheus.yml에 scrape_config 속성을 작성하여 메트릭을 수집할 대상을 IP로 지정하였다. 하지만, 실제 컨테이너 운영환경에서는 스케일링, 재배포, 업데이트 등의 이유로 인해 애플리케이션에 할당된 IP가 동적이기 때문에 바람직한 방법이라고 생각되지는 않는다.
Service Discovery(SD)는 메트릭 수집 대상 컴포넌트에 대한 메타데이터를 갖고있는 대상을 탐색하여 수집 대상에 대한 정보를 Label로 구분하고 항상 최신화 하여 이러한 문제점을 해결할 수 있다.
Label
service discovery를 이해하기 위해 잠깐 Prometheus의 label에 대해 짚고 넘어가야 한다.
Prometheus의 scrape target 은 모두 labels라는 속성이 붙을 수 있는데 kubernetes의 label과 비슷하게 생각할 수 있다. label은 아래와 같은 순서로 적용이 된다.
- Prometheus 서버에서 수집되는 모든 타겟에 붙는 global label.
- 각 scrape 설정마다 기본으로 설정되는
joblabel. - scrape 설정 내에 타겟 그룹마다 설정되는 label.
- relabeling에 의해 생성되는 label.
단계를 차례대로 지나서 설정이되며 이전 단계와 충돌되는 label은 모두 덮어 씌워진다. 여기서 relabeling 이라는 기법을 통해 기존의 label을 변경하거나 값을 합쳐서 새로운 label을 만들수도 있다. relabeling은 아래와 같이 정의하고 새로 labeling이 이루어진다.
relabel_configs:
- source_labels: ['label_a', 'label_b'] # source label들을 정의한다.
separator: ';' # 선택된 label들은 separator 와 함께 접합된다. ("foo;bar")
regex: '(.*);(.*)' # 정규표현식으로 match되는 문자열을 정의한다. (["foo", "bar"])
replacement: '${1}-${2}' # regex에서 match된 문자열을 기준으로 만들 값을 정의한다.("foo-bar")
target_label: 'label_c' # target_label에 replacement 값을 할당한다.
돌아와서
미리 수집 대상에 label을 정의해두고 SD를 통해 얻어진 값을 위의 relabling을 통해 항상 최신 값을 유지할 수 있게 해준다. 원활한 메타데이터 참조를 위해 prometheus에서 미리 정의해둔 설정들이 존재한다. (Kubernetes의 SD 설정, 다른 SD 설정 살펴보기)
TSDB
Time Series database의 약자. Local 스토리지에 저장하는 것이 default이며 Remote 스토리지 통합과 OpenMetrics 포맷으로 Backfilling 등도 지원하고 있다.
Backfilling 이전 시점의 데이터를 채우는 것을 뜻 함.
두 시간 단위로 최신 데이터 블록을 보관하다가 압축을 시도하며 기본 데이터 유지기간은 15일이다.
storage.tsdb.retention.time, storage.tsdb.retention.size 등의 옵션을 통해 데이터 유지기간을 변경하거나 용량제한으로 데이터 유지를 지정할 수 있다.
HTTP Server
TSDB에 저장된 데이터를 외부에서 조회하기 위한 HTTP API 서버. /api/v1로 시작하는 uri를 통해 조회할 수 있다. 자세한 API 이용 방법은 공식문서 참고.
Alertmanager
Prometheus server에서 보내는 알림을 처리하는 컴포넌트. 알림 규칙은 Prometheus server에서 설정하고 Prometheus server는 이 규칙을 통해 Alertmanager로 알림을 보낸다. Alertmanager는 중복 알람을 제거하거나 그룹핑을 하고 이메일이나 PagerDuty, Slack과 같은 reciver integeration에 알맞게 보내는 역할을 한다. 알림이 오지 않도록 하거나 (Silencing / 알림규칙 변경과 다른 개념) 알림을 억제하는 역할을 한다. (Inhibition / 알림 우선순위, 위험순위 등에 따라 하위 경고 알림 등을 배제하는 것)
자세한 Alertmanager 설정은 공식문서 참고.
Prometheus web ui
Prometheus에서 기본적으로 제공하는 Metric UI 도구. PromQL을 통해 원하는 메트릭을 조회할 수 있으나, Grafana를 통해 더 보기좋게 시각화가 가능하기 때문에 일반적으로 Grafana를 선호하는 편.
설치
Kubernetes에 Prometheus를 설치하기 위해 manifest를 다운받고 설치하는 방법도 있지만 필요한 각종 Exporter, Prometheus Server, 시각화 툴 등 여러가지를 다 따로 설치해야하는 번거로움이 있다.
prometheus community에서 제공하는 helm 차트를 통해 아주 간단하게 설치가 가능하다. (helm chart 저장소)
우선 helm repo를 아래와 같이 추가해준다.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
그리고 helm search repo prometheus-community 명령어로 설치가 가능한 차트와 버전 등을 확인할 수 있다.
Github을 통해 저장소에 들어가보면 charts 폴더 내에 유용한 exporter들을 포함한 여러 개의 차트가 존재하는 것을 확인할 수 있다.
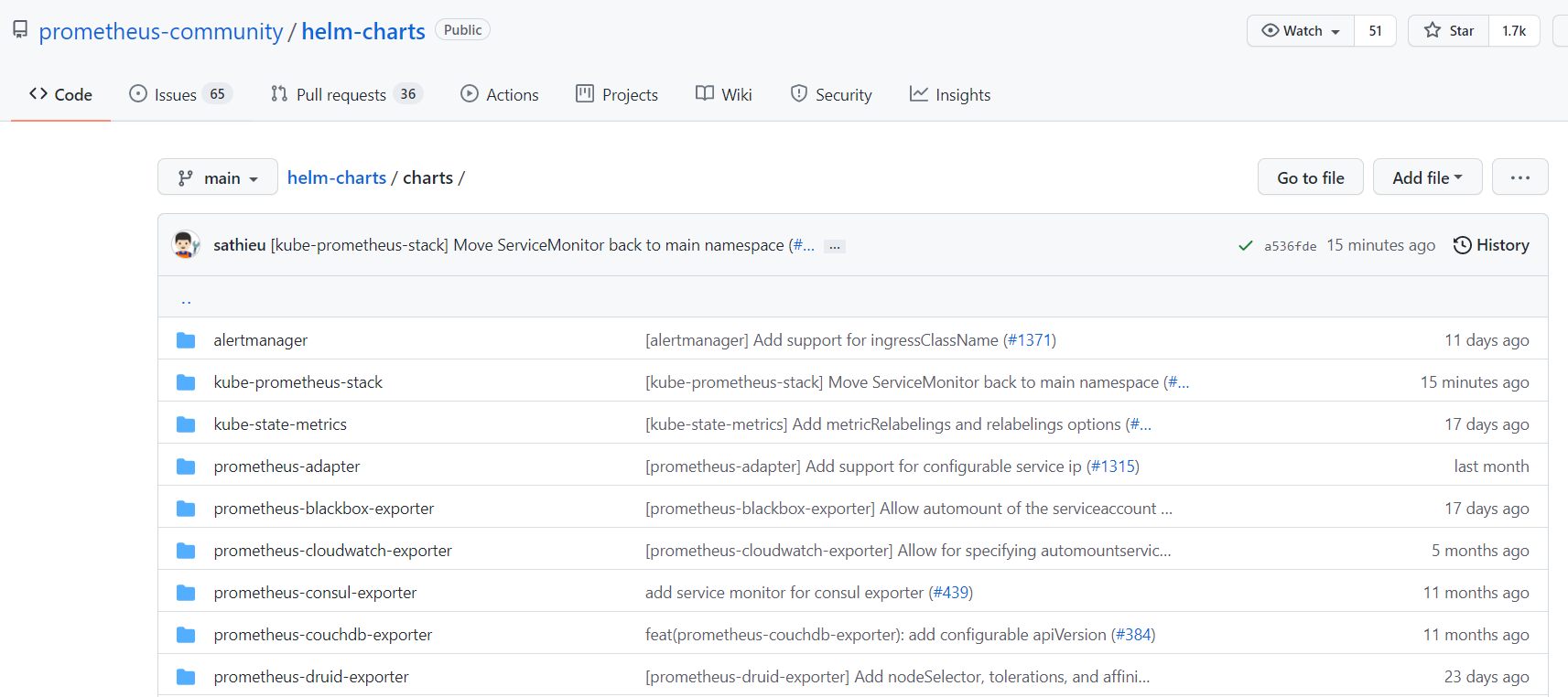
여기서 kube-prometheus-stack 를 선택하여 설치하도록 하겠다. 해당 차트는 비교적 최근에 나온 Prometheus Operator를 이용하여 자동으로 모니터링 스택을 정의하고 내 클러스터에 맞는 설정과 배포 또한 진행한다.
Kubernetes 오퍼레이터 패턴
사용자 정의 리소스(CRD)를 이용하여 애플리케이션 및 해당 컴포넌트를 관리하는 쿠버네티스 익스텐션을 이용하는 패턴. 오퍼레이터는 쿠버네티스의 컨트롤러처럼 동작. (정의한 상태가 되도록 작업 수행) (오퍼레이터 패턴에 대한 자세한 연구는 다음 글에…)
helm 저장소에 prometheus-community를 추가한 뒤에 아래의 명령어로 설치가 가능하다.
helm install -n [TARGET_NAMESPACE] [REALEASE_NAME] prometheus-community/kube-prometheus-stack
아래는 Prometheus Operator를 통해 정의된 사용자 정의 리소스들.
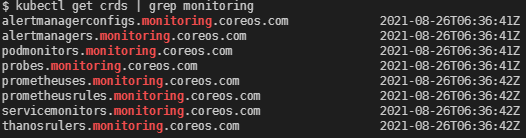
특히 이 차트는 Prometheus server뿐만 아니라 Kubernetes 클러스터 메트릭을 수집할 수 있는 두 가지 Exporter(kube-state-metrics, node-exporter)와 Grafana도 같이 설치해주고 심지어 미리 정의된 대시보드까지 같이 있다.
Prometheus의 구조를 모르더라도 명령어 한 줄로 가장 기본적이면서 공통적인 metric을 바로 수집할 수 있다. Operator가 설치를 완료하기까지 잠시 기다리면 바로 사용이 가능한 Prometheus 서버와 Grafana 대시보드를 확인할 수 있다.
아래의 명령어를 통해 설치가 완료된 것을 확인했다면,
kubectl -n [TARGET_NAMESPACE] get pods -l "release=[RELEASE_NAME]"
포트포워딩을 통해 http://localhost:3000 에서 grafana 대시보드에 접속이 잘 되는지 확인한다.
kubectl -n [TARGET_NAMESPACE] port-forward deployment/prometheus-grafana 3000
kube-prometheus-stack 차트를 통해 설치한 grafana의 관리자 계정과 비밀번호는 아래와 같다.
username : admin
password : prom-operator
만약 port-forward를 이용하지 않거나 localhost를 통해 확인할 수 없는 상황이라면(원격 서버를 통한 작업 등) 아래의 Grafana Ingress 섹션을 확인.
Grafana Ingress
주의 Ingress, Service, Endpoint 등 Kubernetes의 네트워크 관련 오브젝트에 대한 기초 지식이 필요하며 클러스터에서 사용할 수 있는 ingress-controller가 배포되어 있어야 함.
방금 설치한 Grafana는 kubernetes 클러스터 내의 서비스이기 때문에 클러스터의 외부에서 접근하려면 로드 밸런서와 Ingress controller, Ingress가 필요하다. 클라우드 벤더(AWS, GCE, Azure)를 이용한다면 벤더가 제공하는 로드밸런서에 맞는 Ingress controller를 설치하고 Ingress를 만들기만 하면 바로 외부에서 접근이 가능하겠지만, On-premise 환경에서는 로드밸런서를 구축하는게 어렵고 불확실한 일이기 때문에 다른 방법을 써야한다.
On-premise 환경에서 할 수 있는 방법은 nginx-ingress-controller를 설치하고 이 서비스를 NodePort나 ExternalIP 방식으로로 노출시켜 접근하는 것이다. MetalLB 같은 BareMetal용 LB 컴포넌트도 있긴 하지만 어디까지나 베타 버전이기도 하기 때문에 조심스러움.
설치는 공식 문서를 확인. 아래는 nginx-ingress-controller가 클러스터 내의 서비스에 외부 접근을 전달하는 그림.
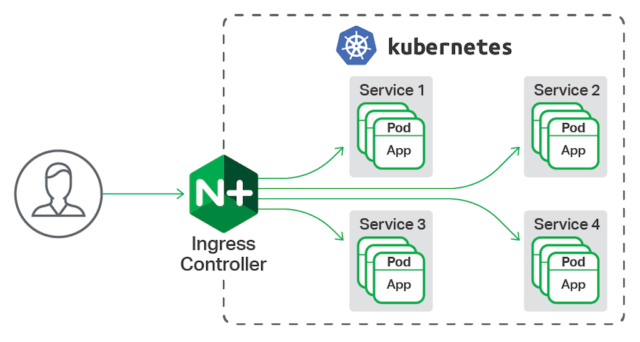
이런 식으로 nginx-ingress-controller를 설치하여 구성하였다면 아래와 같이 Ingress resource를 생성하는 manifest를 작성한다.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: "nginx"
ingress.kubernetes.io/ssl-passthrough: "true"
kubernetes.io/ingress.allow-http: "true"
nginx.ingress.kubernetes.io/rewrite-target: /$1
name: grafana-ingress
namespace: default
spec:
rules:
- http:
paths:
- path: /grafana/?(.*)
pathType: Prefix
backend:
service:
name: prometheus-grafana
port:
number: 80
nginx-ingress 서비스를 NodePort로 구성하였기 때문에 path와 rewrite-target 속성을 이용하여 /grafana뒤에 오는 uri를 응답으로 다시 쓰도록 하였다. 이렇게하면 기본 uri가 마치 http://<노드IP>:<Ingress 서비스포트>/grafana 인 것 처럼 작동하고 서버에서 보내는 redirect 요청도 정상적으로 동작한다. 그러나 해당 uri로 접속하니 redirect가 발생했고 기대한 요청은 http://<노드IP>:<Ingress 서비스포트>/grafana/login이였지만 실제로 발생한 요청은 http://<노드IP>:<Ingress 서비스포트>/login 이였다.
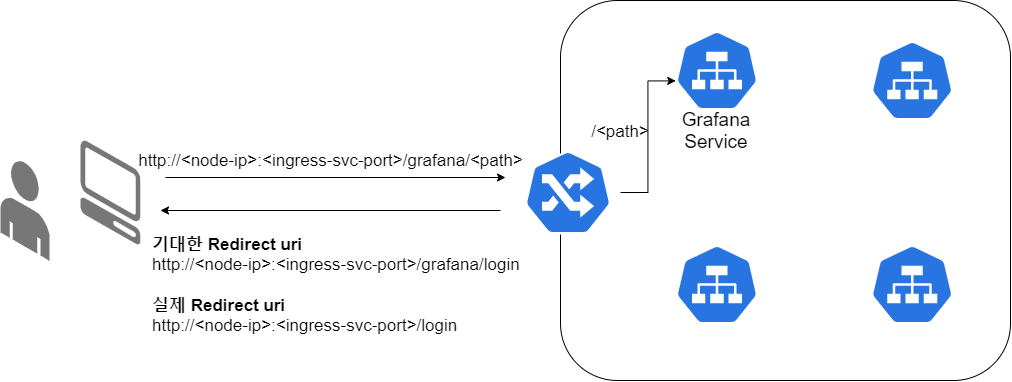
해결 방법은 Grafana 자체에서 helm 차트를 통해 배포하는 grafana 설정파일(grafana.ini)에 서버 root_url과 관련된 설정을 넣는 것.
helm 차트를 클론하여 수정하는 방법도 존재하지만, ConfigMap에서 prometheus-grafana를 찾아 아래 부분을 추가하면 된다.
[server]
domain = example.com
root_url = %(protocol)s://%(domain)s:%(http_port)s/grafana/
serve_from_sub_path = true
nginx-ingress가 NodePort로 서비스되면서 reverse proxy처럼 동작해 발생한 문제였다. 이렇게 수정하고나면 http://<노드IP>:<Ingress 서비스포트>/grafana uri를 통해 정상적으로 배포된 grafana에 접속이 가능하다. (참고 : Run Grafana behind a reverse proxy)