프로젝트를 하게 된 계기
빅데이터 시스템 설계 과목 프로젝트
영화 취향이 같은 사람들끼리 할 수 있는 SNS가 있으면 좋겠다고 해서 만들게 되었다.
Stack
- Language : Python, Javascript
- Framework : Django, Vue
- DBMS : Mongodb
- Library
- scikit-learn : K-means clustering에 사용
- Djongo : Django에서 공식지원을 하지 않는 Mongodb와의 connect을 위해 사용
- d3.js : 사용자, 영화 데이터 시각화를 위해 사용
Diagrams
-
시스템 아키텍쳐
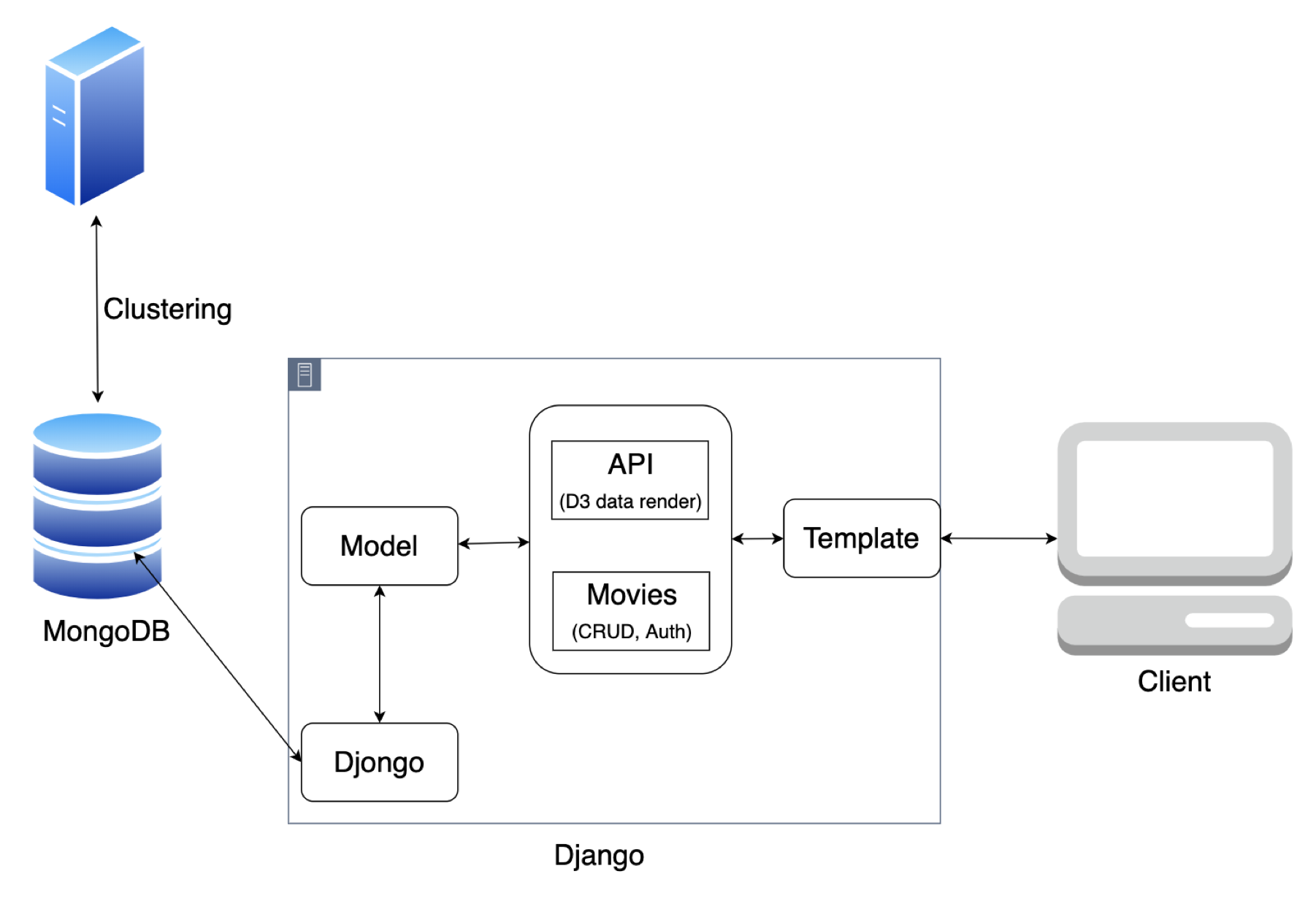
-
Class diagram
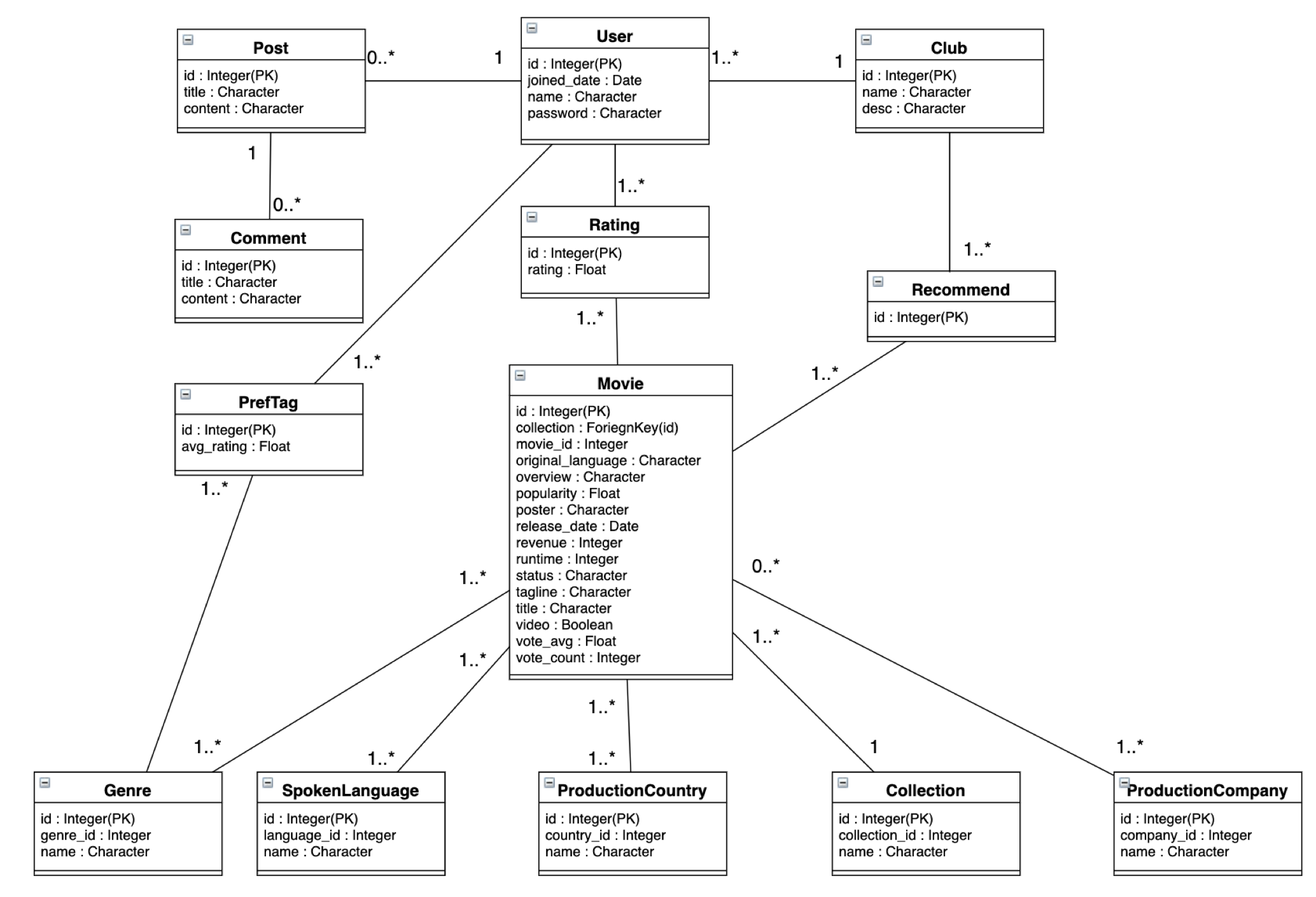
주요 기능
- 영화 별 평점 확인
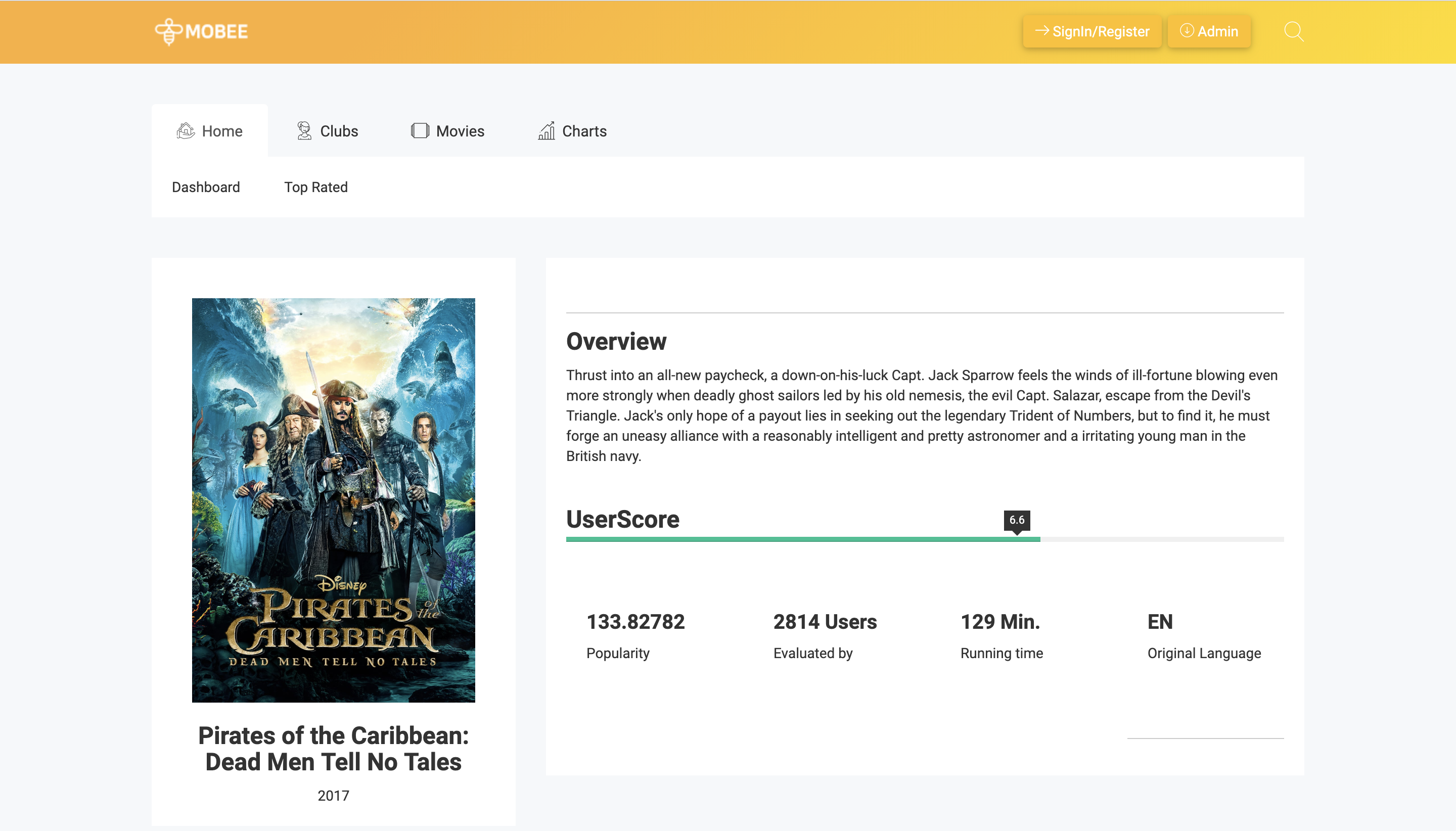
- 년도별, 장르 인기순위 확인
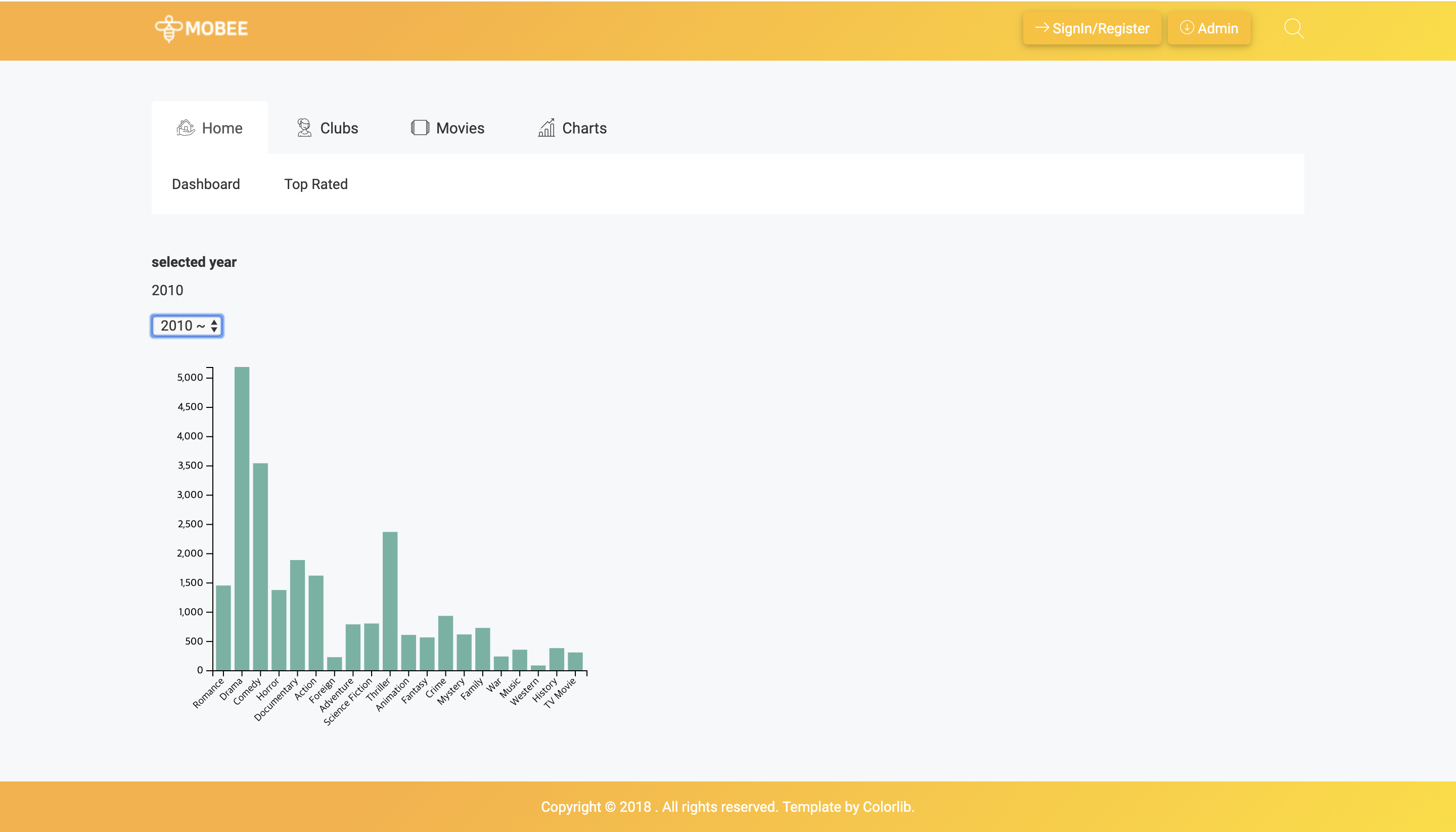
- 평점을 토대로 사용자 그룹핑(Clustering)인
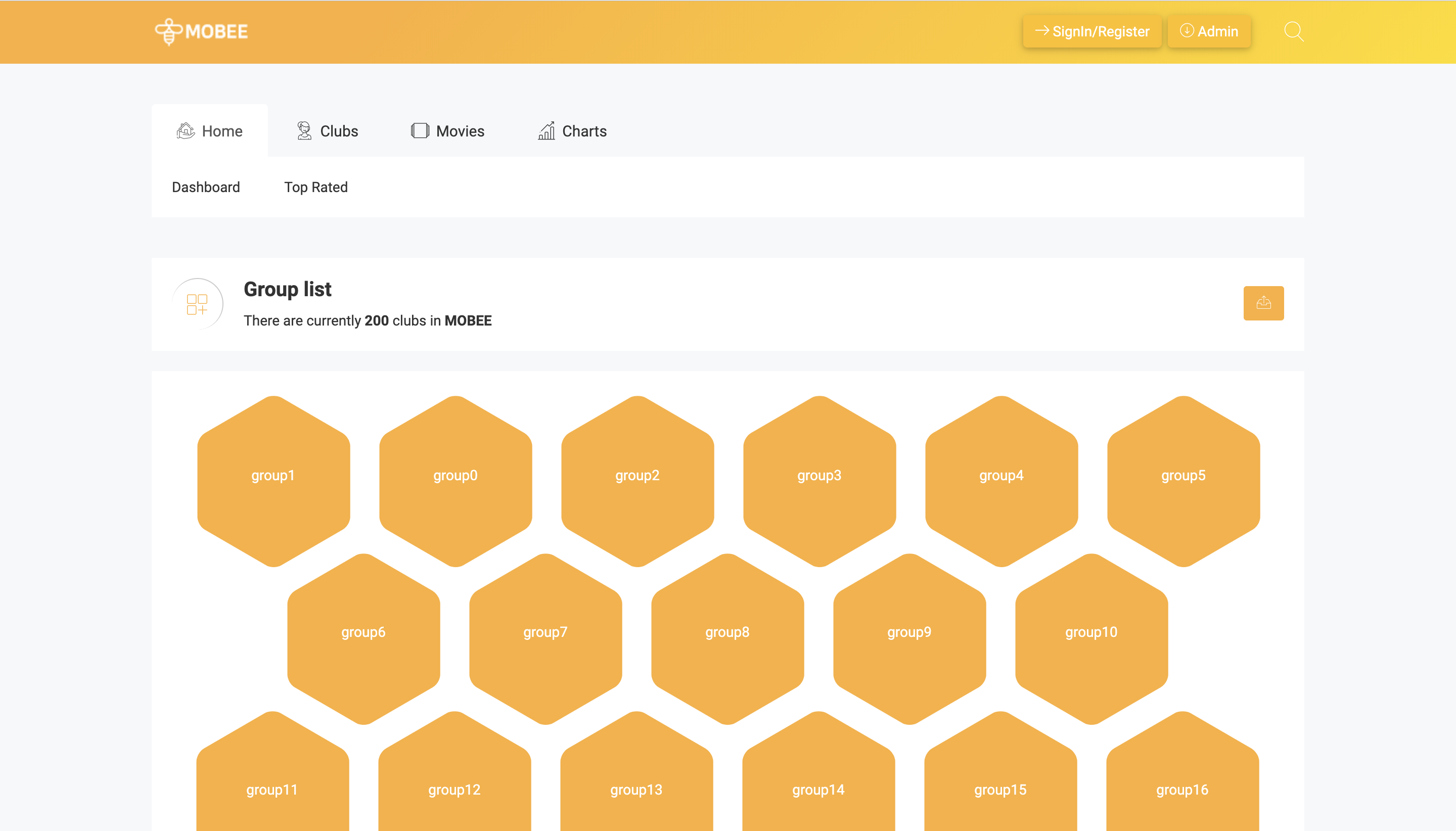
- 그룹 별 SNS 형 게시판
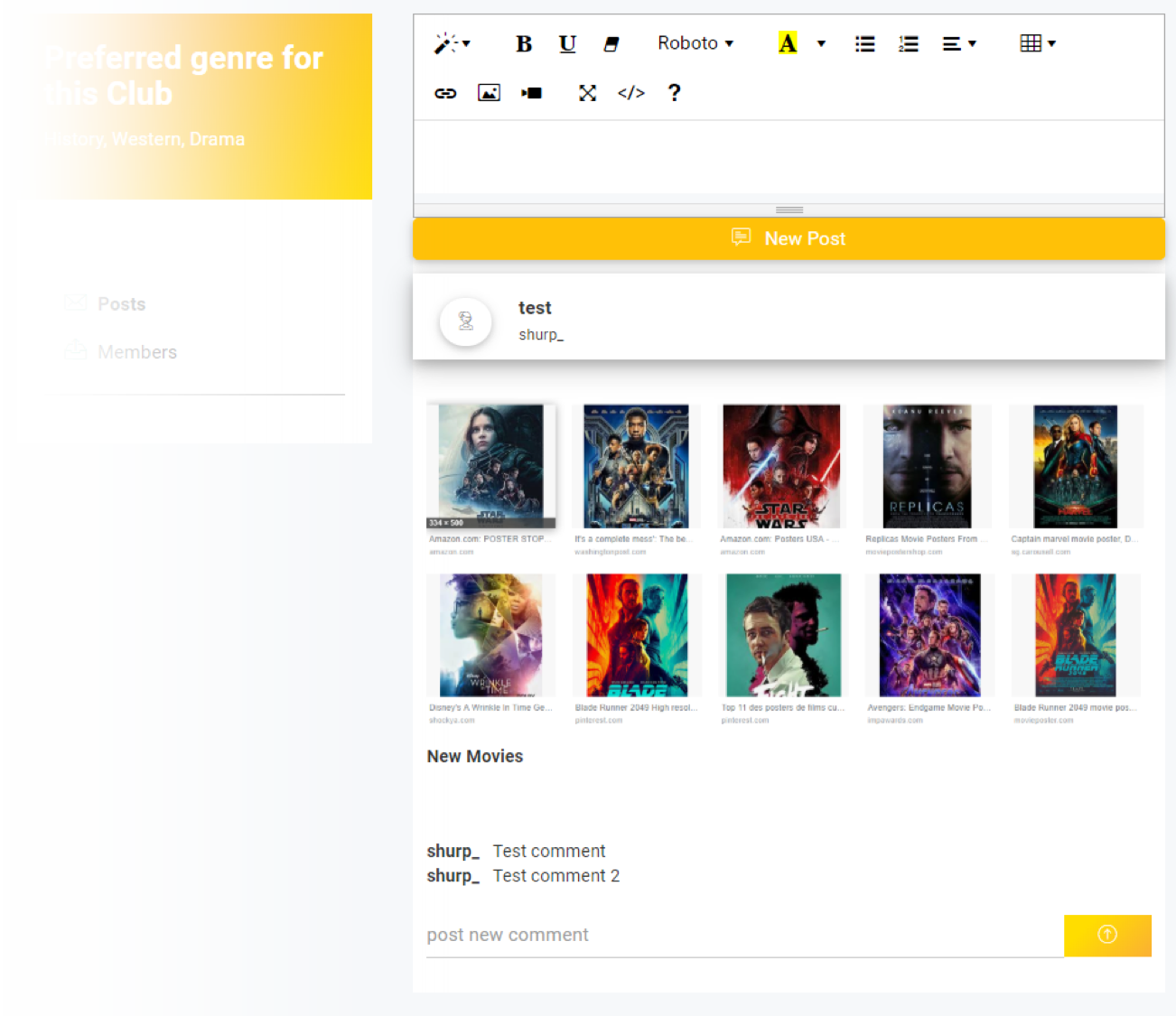
- 그룹 별 영화 평점 데이터 시각화
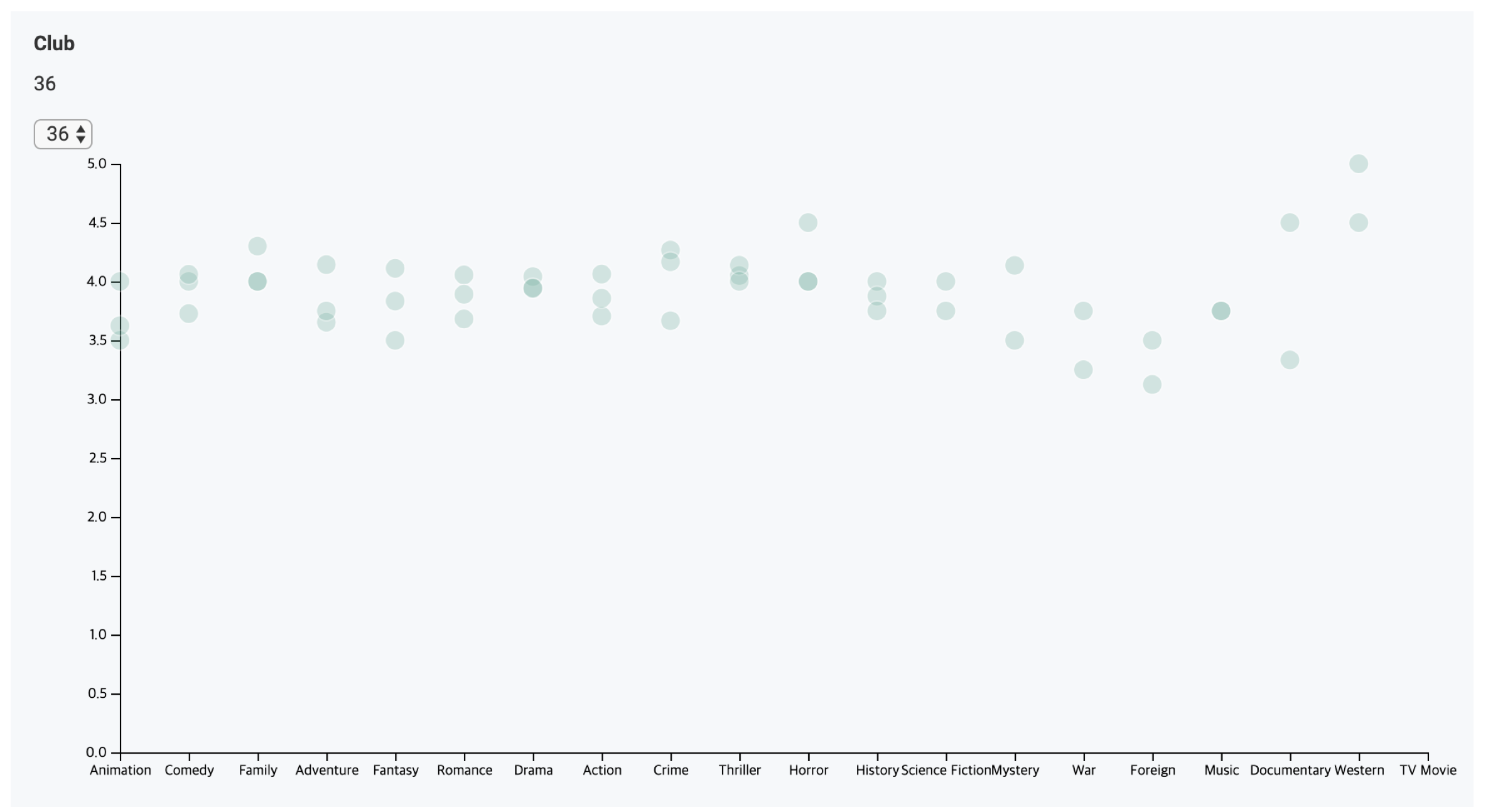
담당 파트 및 고찰
- Class Modeling
- 모든 클래스를 modeling 했지만, 큰 어려움은 없었다.
- 후술할 Djongo 때문에 애 좀 먹었음..
- Authentication(using Django abstract user)
- 잘 이해하고 있다는 전제 하에 바로 사용하기에는 정말 좋지만, 공부에는 좋지 않은 듯..(기본 User 클래스가 너무 많은 것을 제공함.)
- Django-MongoDB 연결 환경 구성(using Djongo)
- Djongo에서 MongoDB의 가장 큰 장점 중 하나인 Embedded document를 완벽히 지원하지 않아서 RDBMS처럼 되어버렸다.
- 그럼에도 불구하고 MongoDB 특유의 빠른 데이터 조회, 처리가 가능했다.
- 애초에 ORM을 기본으로 하는 framework에서 NoSQL을 쓰려고 했던게 잘못일지도..
- 데이터 시각화 (using d3.js)
- 처음 써보는 시각화 라이브러리
- 바닥부터 하려니 어려웠는데 cheat sheet을 통해 필요한 부분만 빠르게 습득
- 그래프 그리기 말고도, 데이터로 할 수 있는 모든 것을 가능하게 하는 라이브러리라는 것을 깨달음.
- K-means 클러스터링
- 사실 이 부분은 담당 팀원이 따로있었지만, 클럽별 영화 평점데이터 시각화 과정 전에 나름대로 해봄. (나중에 비교해보니 코드는 거의 비슷)
- Clustering 기준을 장르 별 평점 데이터로 했기 때문에, 사용자가 평가한 모든 영화를 장르별 평균으로 abstract하는 과정이 필요했음(장르가 24개.. 24차원..)
- K-means 모델 학습, 분류에 대한 전처리, 후처리를 어떻게 해야할 지 알 수 있었다.
실제 중요한 학습과 클러스터링은 scikit-learn이 다 함..ㅋㅋ
한 마디
- 발표는 끝났지만 완성시켜서 배포까지 해봐야겠다.
(배포를 못 한 이유는 free tier짜리 ec2로는 200MB가 넘는 DB의 인덱싱 과정 중 out of memory 에러가 떠서..t2.micro 메모리 상향좀 ㅠㅠ
++ RDS를 이용하면 되긴 하지만, 2주에 3만원이 넘게 나왔던 기억이 있어 엄두가 안난다)